Your team has two stories to consider for next sprint.
One involves supporting a new input source. What is needed to be done is pretty clear. Create the schema. Create the input API. Create the ETL. Test, document, and deploy. There is work to do, but it’s well understood work. The team estimates it to be 2 points.
The other is upgrading a library your backend uses. It could be almost no work. Update the dependency version and your automated tests show everything works fine. It’s probably a little work. One or two things might need to be updated to work with it. It might be a lot of work. Some functionality your software uses might be broken with the upgrade and will require major revisions. The team estimates it to be be 2 points.
You enter sprint planning and are considering which stories to add. Both of these 2 point stories are candidates. Should you treat them the same?
Of course not. But point estimating pushes you to do exactly that.
I’m assuming if you are reading this blog you are a nerd, so lets describe these stories using statistics. Maybe the probability distributions for how long these stories will take looks something like this.
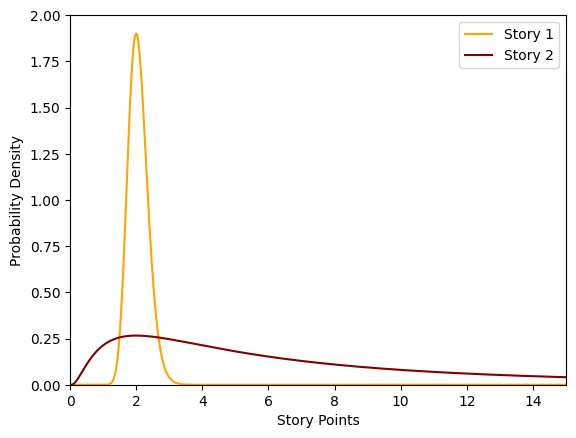
The first story has a small variance. An estimate of 2 story points is pretty safe. Sure we can’t say exactly that it will take whatever 2 points ends up being with your team’s velocity. It may take a little more, or a little less. But over enough time, your overestimates should more or less cancel out your underestimates.
The second story is a completely different beast. It has a very large variance. And it has a heavy right skew with a very long tail. It’s not even clear what the estimate should be.
Should it be the mean value of the distribution? In order for the notion that that underestimates cancel out the overestimates to apply, that should be the target. But the mean value is usually going to be an overestimate. You will have to schedule more time for the story than it will probably take, which makes fitting it in a schedule harder than it might need to be. And you still don’t get rid of the risk that you will have significantly underestimated the time. And telling your PM that your underestimate is balanced by all your other overestimates won’t generate much sympathy if that story is what delays the product.
Should it be the mode value, or the most likely estimate? If your team is evaluated on how often you estimate correctly, this is the logical choice. But it is also a dangerous choice. More often than not you will underestimate the task, sometimes by a lot.
Should the estimate be the median value? 50% of the time it will take longer, 50% it will take less time. That seems to be a decent compromise. You will overestimate as often as you underestimate. Except the scales will be different. Your overestimates are capped. No task will take negative days to complete. And your worst underestimates may be orders of magnitude off. The thing you thought would take a few days could take weeks. This is far more impactful than the task that you thought would take days but just took an afternoon.
Does this mean the second story can’t be planned at all? Of course not. There are ways to address the uncertainty, as long as you are aware it is there.
It can be handled by time boxing it. Schedule a day for it. If it can be done in that time, great! If it can’t, it goes back on your backlog, with the knowledge that it is more complicated than you initially hoped for. Yes, you risk spending a day working on something that will not directly provide any benefit. But you safeguard yourself from spending weeks working on something you thought would take an afternoon.
Or you can just acknowledge the risk. Have someone dedicated to it, as long as it takes. Hopefully they will be done quickly, but understand it might take longer. Don’t commit to plans that are dependent on that engineer being available for a new story next sprint. Sure, have something ready for them to work on once they are done, but make sure it isn’t something particularly time sensitive.
But again, note than in order to do either of these, you need to know this task has a lot of uncertainty involved in it. You need to plan for it differently than you would the first story.
Which means estimating the story points of a new feature is insufficient. You also need to know the level of uncertainty.